EDITOR: For TensorBase, there are many changes from m0. What remains unchanged is the original intention of TensorBase to service all the people and business in this era!
Today, I am pleased to announce the milestone 0 of TensorBase (called Base for short as following).
Base is a modern engineering effort for building a high performance and cost-effective bigdata analytics infrastructure in an open source culture.
Base is written in the Rust language and its friend C language.
Philosophy
First principle
Base is a project from the “first principle”. That is, unlike many other NoSQL/NewSQL products which claimed to be based on Google Spanner or similar, Base is based on almost nothing.
The first principle for Base is just, only starting from current available commodities and software tools(a.k.a., languages and operation systems), asks three questions:
-
(Dream #1) What limit can Base reach, facing the planetary data tide?
-
(Dream #2) What an exciting community can Base build around?
-
(Dream #3) How can Base grant the public the ability to control the big data?
Shared Something
In the design of distributed data systems, there are two architectures often talked: shared-nothing and shared everything.
These are two extremes. Commonly, shared nothing is considered to be more scalable. But, it is suboptimal or even bad for non-trivial problems. For a database like product, nothing to share is awkward. For many global-viewpoint operations, it most likely requires global data movement. The remaindering is what/which/how data to remove. Easy to reason that a way of being ignorant of the environment and context is impossible to achieve the global optimum.
OTOH, share everything, in fact, is idealized. Image that we have single big infinitely expandable computer. All problem solved… So, share everything truly compromises on scalability and has requirements to hardware.
Shared Something is a dynamic best effort architecture sitting between shared nothing and everything, which achieves best performance via finitely sharing partial necessary contexts which are environments and computing dependent. This is just a highly abstract proposal in that Base is still in answering it. The direction to approach is, self adaptive computing via some shared infrastructures in the society of decentralization. Here, shared infrastructures do not mean centralized components. It could be just mechanisms to allow efficient information sharing/exchanging.
Architectural Performance
Performance is one of core architectural designs. Long-year experience of performance engineering taught me that if performance cannot be considered architecturally first, the final evolution is just the performance collapse that cannot be repaired unless rewritten (but usually you have no chance to rewrite).
Scalability is another character often talked by projects. The truth is, good scalability does not mean high performance. Poor performance implementations are probably easier to achieve high scalability (in that you use a relative low baseline which may shows no bottleneck in any aspects). High scalability within low performance is cost expensive, economic killer and high-carbon producer…
Via architectural performance design, with Dream #1 in mind, Base is unique.
System
For short, the architectures are summarized in the following figure.

System sketch of TensorBase
In this system, some parts are interesting, and some parts are indeed well-known (like in papers) but ridiculously no open-source counterpart. The details of components is out the scope of this post in that innovation big bangs here.
One of core efforts of Base is to provide a highly hackable system for the community under the guidance of Dream #2.
The system of Base is built with Rust and C. Rust lays a great base for system engineering. C is used to power a critical runtime kernel for read path(query) via a high-performance c jit compiler.
The rationale for C is that Base needs a jit compiler for full performance (it is pity that recently I see some project say its ability to call vcl vectorized functions as “fastest” database…).
By lowering the contributing bar, Base hopes more people can enjoy to engage in the community.
On the top of comfortable languages, the nature of “first principle” of Base, allows contributors to be more pleased to build elegant performance critical system with the help of the external excellent. For instance, to use modern Linux kernel’s xdp in network stack to enable a scalable and cost-efficient RDMA alternative on commodity network (io_uring is that new standard tool in lower performance).
Note: storage and C jit compiler in the system are not released or released in binary form in the m0 (they are under heavy changes) but will come later.
Launch
Let see what’s in Base m0.
In m0, Base provides a prototyping level but full workflow from the perspective of simple data analysis tools:
- command line tool: baseops
- provides a subcommand import, to import csv data into Base
- provides a subcommand table, to create a table definition
- command line tool: baseshell
- provides a query client (now client is a monolithic to include everything)
- m0 only supports query with single integer column type sum aggregation intentionally.
Quick Start
let’s do quick start:
- run baseops to create a table definition in Base
cargo run --bin baseops table create -c samples/nyc_taxi_create_table_sample.sqlBase explicitly separates write/mutation behaviors into the cli baseops. the provided sql file is just a DDL ansi-SQL, which can be seen in the samples directory of repo.
- run baseops to import nyc_taxi csv dataset into Base
cargo run --release --bin baseops import csv -c /jian/nyc-taxi.csv -i nyc_taxi:trip_id,pickup_datetime,passenger_count:0,2,10:51Base import tool uniquely supports to import csv partially into storage like above. Use help to get more infos.
- run baseshell to issue query against Base
cargo run --release --bin baseshell
Benchmark
New York Taxi Data is an interesting dataset. It is a size-fit-for-quick-bench real world dataset. And, it is often used in eye-catching promotional headlines, such as “query 1.xB rows in milliseconds”. Now, I compare Base m0 against another OLAP DBMS ClickHouse(20.5.2.7, got in July, 2020):
-
The Base csv import tool is vectorized. It supports raw csv processing at ~20GB/s in memory. The ~600GB 1.46 billion nyc taxi dataset importing run saturates my two SATA raid0 (1GB/s) and finished in 10 minutes. ClickHouse run at 600MB/s in the same hardware.
NOTE: Because ClickHouse does not support csv partially importing. So, 600MB/s ClickHouse importing is done in a ClickHouse favored way: to use a column-stripped csv. 600GB for Base is much larger than node’s memory, but the size of column-stripped csv for ClickHouse is memory-fit (and the cacheline is fully utilized). The official reports that ClickHouse on 8-disk raid5 takes 76 minutes to finish.
-
for the following simple aggregation,
select sum(trip_id-100)*123 from nyc_taxiBase m0 are 6x faster than ClickHouse (20.5.2.7): Base runs in ~100ms, ClickHouse runs in 600ms+.
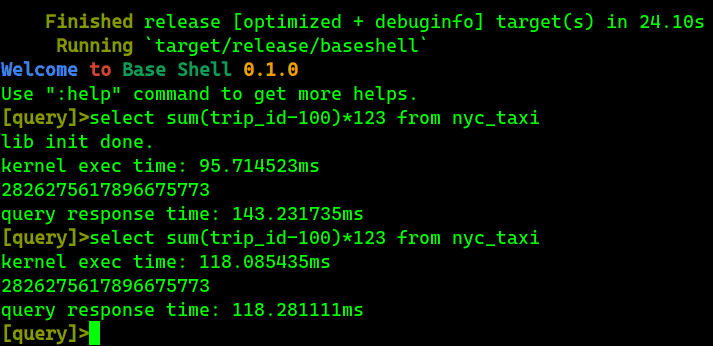
Aggregation results in Base's baseshell
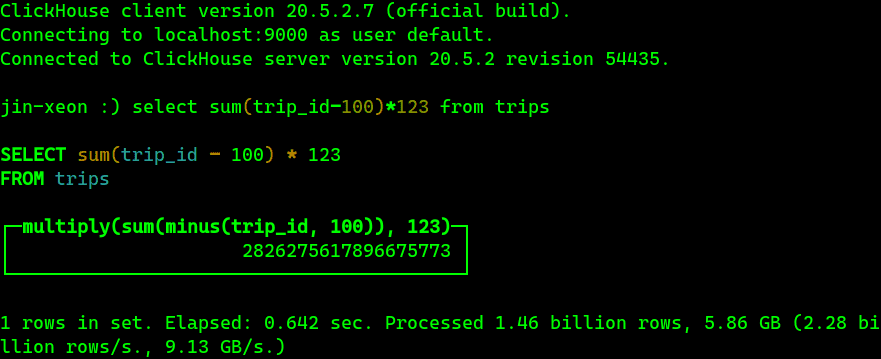
Aggregation result in ClickHouse client
Note #1: The official ClickHouse configs are used. The bench tests run several times, and use the best result for ClickHouse. (Then, this is just an in-memory query in same hardware, no actual disk io is involved and the ClickHouse result is on par with officially listed single node result).
Note #2: it is interesting to see a bug in Base’s jit compiler: it is expected that the second run of kernel should be shorter than it first run.
Note #3: for showing the version of ClickHouse, the figure just picks the first run screenshot after client login. This does not affect the result in that the ClickHouse is in the server-client arch.
Here, what I want to emphasize that the performance of Base for such trivial case is almost hitting the ceiling of single six-channel Xeon SP. That is because the parallel summation is just a trivial memory bandwidth benchmarking loop. There are tiny improvement rooms stay tuned:
- ~15ms of current jit compilation (not trivial, after above bug fixed, extra 15-20ms saving);
- 10-20ms of current naive parallel unbalancing (trivial for just fixing, not trivial for architectural elegance);
Although Base m0 just gives a prototype, it is trivial to expand to all other operations for a single table in hours. Welcome to Base community!
Meeting in Community
The true comparison is that, thanks to the appropriate ideologies (not only first principle…year-after-year experiences, practices, thoughts) and tools (Rust and C…), two-month Base can crush four-year ClickHouse in performance.
Base is ambitious: from storage, to sql compilation, to mixed analytics load scheduling, to client, to performance engineering, to reliability engineering, to ops engineering and to security and privacy. Take a glimpse:
- Base invents a data and control unified linear IR for SQL/RA (I called “sea-of-pipes”).
- Base favors a kind of high level semantic keeping transforms from IR to C which provides lighting fast, easy maintaining code generations.
- Base supports to write C in Rust via proc_macro and in future it is not hard to provide an in-Rust-source error diagnoses and debugging experiences. OTOH, this allows to use any Rust logics to generate arbitrary C templates.
- Base is in prototyping a new tiered compilation which sunshines in short-time queries compared to other open-source LLVM IR based counterparts.
- …
If you are from Rust or C communities, please give Base a star. To help Base being the strong community voice: we can build best bigdata analytics infrastructure in the planet.
If you are having some of dreams which Base have, we are the same data nerds. Join us!